一、MVCC架构设计与实现原理
1.1 存储引擎层架构
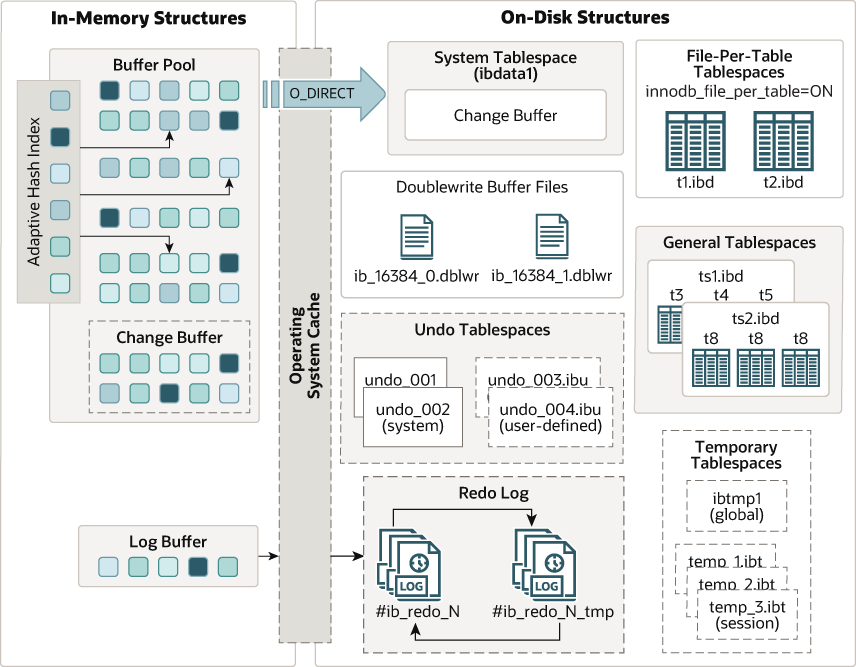
InnoDB采用分层存储架构实现MVCC机制:
内存结构:
- Buffer Pool:数据页缓存池(默认128MB)
- Undo Log Buffer:事务回滚日志缓存(默认16MB)
- Change Buffer:非唯一索引更新缓冲
磁盘结构:
- 聚簇索引B+树(主键索引)
- 二级索引B+树
- Undo Log段(回滚段)
- Redo Log文件组
1.2 多版本数据存储
每个数据页(16KB)包含版本链头指针,通过DB_ROLL_PTR串联历史版本。Undo Log采用段式存储管理,每个回滚段包含1024个undo slot。
Undo Log类型:
-- 插入操作日志
UNDO_INSERT = {
type: 'INSERT',
table_id: 0x0012,
old_data: null
}
-- 更新操作日志
UNDO_UPDATE = {
type: 'UPDATE',
table_id: 0x0012,
old_data: {id:1, balance:100},
index_updates: [
{index_id: 0x01, old_value: 'Alice'}
]
}1.3 事务ID管理
事务系统维护全局事务ID分配器:
- trx_sys结构管理活跃事务列表
- 事务ID(trx_id)分配规则:
- 只读事务:trx_id=0
- 读写事务:从全局计数器获取递增值
- 事务可见性判断公式:
visible = (trx_id < view_up_limit_id) && (trx_id == creator_trx_id || trx_id not in active_trx_set)
二、版本链构建与遍历机制
2.1 行记录格式解析
以Compact行格式为例:
+--------+---------+---------+---------+-----+
| Header | Col1 | Col2 | TRX_ID | PTR |
+--------+---------+---------+---------+-----+
| 0x80 | 'Alice' | 100.00 | 0x00001 | 0x7F|
+--------+---------+---------+---------+-----+- Header:包含删除标记、列数信息
- TRX_ID:6字节事务ID(最大2^48事务)
- PTR:7字节回滚指针(指向UNDO_LOG地址)
2.2 版本链构建过程
事务更新操作流程:
- 获取行排他锁(X Lock)
- 拷贝当前版本到Undo Log
- 修改数据并更新TRX_ID
- 将旧版本PTR指向新Undo Log
// InnoDB内核代码片段(storage/innobase/row/row0upd.cc)
void row_upd_clust_step() {
undo = trx_undo_report_begin(); // 开始记录undo
old_rec = btr_copy_record(); // 复制旧记录
row_upd_rec(update, rec); // 更新记录
trx_undo_report_end(undo); // 提交undo记录
}2.3 版本链遍历算法
查询时的版本选择过程:
- 从当前记录开始遍历
- 检查每个版本的TRX_ID可见性
- 找到第一个可见版本或到达链尾
遍历伪代码:
def find_visible_version(row, read_view):
current = row
while current:
if is_visible(current.trx_id, read_view):
return current
current = current.roll_ptr
return None # 无可见版本(已删除)三、Read View实现细节
3.1 快照生成机制
Read View创建时获取系统状态:
- low_limit_id = trx_sys->max_trx_id
- up_limit_id = trx_sys->min_active_trx_id
- active_trx_ids = 当前活跃事务ID列表
内存数据结构:
struct read_view_t {
trx_id_t low_limit_id;
trx_id_t up_limit_id;
trx_id_t creator_trx_id;
ids_t active_trx_ids;
ulint n_trx_ids;
};3.2 可见性判断优化
InnoDB采用二分查找优化活跃事务判断:
bool read_view_sees_trx_id(
const read_view_t* view,
trx_id_t trx_id)
{
if (trx_id < view->up_limit_id) return true;
if (trx_id >= view->low_limit_id) return false;
return !bsearch(&trx_id, view->active_trx_ids,
view->n_trx_ids, sizeof(trx_id_t),
trx_id_compare);
}四、隔离级别实现差异深度分析
4.1 READ COMMITTED实现
关键特征:
- 每次SELECT新建Read View
- 使用语句级快照
- 可能产生幻读
锁机制配合:
UPDATE accounts SET balance = balance - 100
WHERE user_id = 123; -- 持有X锁直到事务结束4.2 REPEATABLE READ实现
特殊处理:
- 使用事务级快照
- 间隙锁防止幻读
- 唯一索引优化:对唯一索引等值查询不使用间隙锁
锁范围示例:
表结构:id INT PRIMARY KEY, name VARCHAR(20)
查询:SELECT * FROM t WHERE id > 100 FOR UPDATE;
锁定范围:(100, +∞)五、生产环境优化实践
5.1 参数调优建议
关键参数配置:
# 控制Undo Log清理速度
innodb_purge_threads = 4
innodb_purge_batch_size = 300
# 长事务监控阈值
innodb_rollback_segments = 128
innodb_max_undo_log_size = 1G
# 版本链遍历优化
innodb_read_ahead_threshold = 565.2 监控与诊断
常用监控命令:
-- 查看活跃事务
SELECT * FROM information_schema.innodb_trx
WHERE TIMEDIFF(now(), trx_started) > '00:00:10';
-- 分析Undo空间使用
SELECT
TABLESPACE_NAME,
FILE_SIZE/1024/1024 as size_mb,
ALLOCATED_SIZE/1024/1024 as alloc_mb
FROM information_schema.FILES
WHERE FILE_TYPE = 'UNDO LOG';
-- 检测版本链长度
SELECT
TABLE_NAME,
INDEX_NAME,
AVG(`NUMBER_RECORDS`) AS avg_versions
FROM information_schema.INNODB_BUFFER_PAGE
WHERE PAGE_TYPE = 'INDEX'
GROUP BY TABLE_NAME, INDEX_NAME;六、典型问题解决方案
6.1 版本链过长问题
症状表现:
- 查询性能逐渐下降
- Undo表空间持续增长
- 出现Snapshot too old错误
解决方案:
- 优化事务大小,减少单事务修改量
- 定期清理历史快照
SET GLOBAL innodb_purge_batch_size = 1000; SET GLOBAL innodb_max_purge_lag = 1000000;
6.2 快照隔离与锁冲突
典型死锁场景:
事务A: SELECT ... FOR UPDATE (持有间隙锁)
事务B: INSERT INTO ... (请求插入意向锁)解决方案:
- 启用死锁检测
innodb_deadlock_detect = ON innodb_lock_wait_timeout = 30 - 业务层重试机制
七、新型硬件环境优化
7.1 NVMe SSD优化
配置建议:
innodb_io_capacity = 20000
innodb_io_capacity_max = 40000
innodb_flush_neighbors = 07.2 持久内存应用
使用PMEM作为Undo Log存储:
innodb_undo_directory = /mnt/pmem
innodb_undo_log_encrypt = OFF八、版本演进与未来方向
8.1 MySQL 8.0改进
重要更新:
- 原子DDL(Atomic DDL)
- 增强型数据字典
- 直方图统计信息
8.2 云原生架构适配
变化点:
- 分布式事务支持(XA增强)
- 计算存储分离架构
- 快照导出/导入优化
九、工程实践建议
索引设计原则
- 主键字段不宜过大
- 避免频繁更新的列作为二级索引
- 组合索引遵循最左匹配原则
事务编写规范
- 事务代码块尽量简短
- 避免在事务中进行网络调用
- 显式设置隔离级别
版本升级策略
- 先升级从库观察
- 使用mysql_upgrade工具
- 验证MVCC相关参数兼容性
十、实践中应该深度思考以及解决的问题
- 如何设计可线性化的分布式MVCC?
- 在HTAP场景下如何平衡OLTP与OLAP的版本需求?
- 当版本链长度超过undo表空间容量时,系统如何保证事务安全?
通过以上的内容,文章系统性地阐述了InnoDB MVCC的实现细节、优化手段及工程实践要点。建议读者结合实际工作场景,参考本文提供的配置参数和监控方法,建立完整的数据库性能优化体系。对于关键业务系统,应当定期进行MVCC健康度检查,确保版本链机制高效运行。最后我们应该在实践的过程中思考最后给出的三个问题。